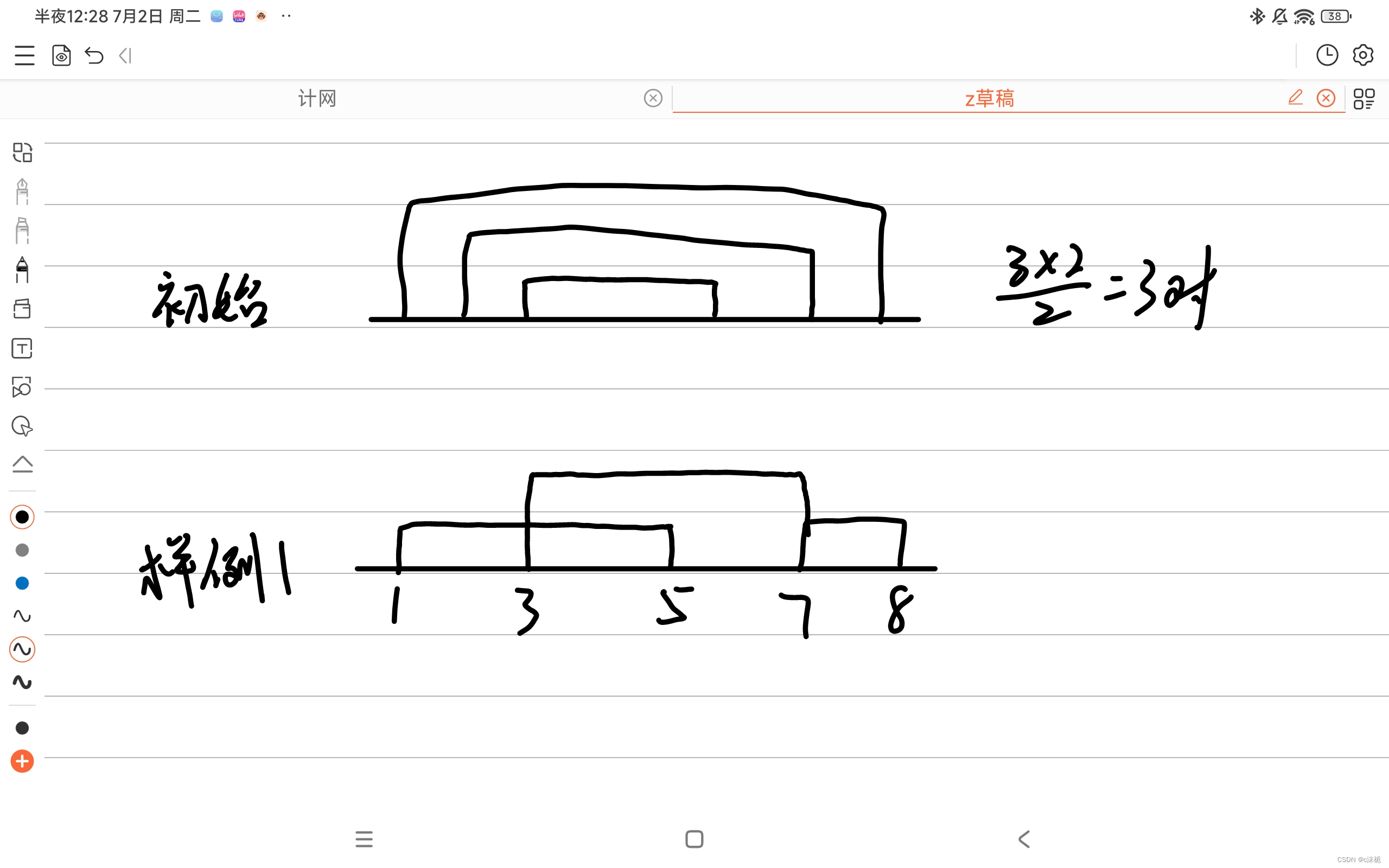
注:演示环境需要一个可用的cuda环境,可执行两个命令进行验证
1.nvidia-smi
2.nvcc -V
若出现正确输出,可继续博客以下的操作步骤,否则请确认是否已经安装或已配置环境变量,若未安装则转到博客:深度学习项目GPU开发环境安装-CSDN博客
进行配置安装cuda环境。
1.安装PyTorch
1) 安装Anaconda
Anaconda 是一个用于科学计算的 Python 发行版,支持 Linux, Mac, Windows, 包含了众多流行的科学计算、数据分析的 Python 包。
1. 先去官方地址下载好对应的安装包
下载地址:https://www.anaconda.com/download/#linux
2. 然后安装anaconda
bash ~/Downloads/Anaconda3-2023.03-1-Linux-x86_64.shanaconda会自动将环境变量添加到PATH里面。
如果后面你发现输入conda提示没有该命令,那么你需要执行命令 source ~/.bashrc 更新环境变量,就
可以正常使用了。
如果发现这样还是没用,那么需要添加环境变量。
编辑~/.bashrc 文件,在最后面加上。
export PATH=/home/bai/anaconda3/bin:$PATH注意:路径应改为自己机器上的路径
保存退出后执行: source ~/.bashrc
再次输入 conda list 测试看看,应该没有问题。
2) 安装pytorch
首先创建一个anaconda虚拟环境,环境名字可自己确定,这里本人使用mypytorch作为环境名:
conda create -n mypytorch python=3.9
安装成功后激活mypytorch环境:
编辑~/.bashrc 文件,设置使用mypytorch环境下的python3.9
alias python='/home/bai/anaconda3/envs/mypytorch/bin/python3.9'注意:python路径应改为自己机器上的路径
保存退出后执行: source ~/.bashrc
该命令将自动回到base环境,再执行 conda activate mypytorch 到pytorch环境。
conda退出base环境
配置一下,让它一开始不启动base
conda config --set auto_activate_base false安装pytorch
在所创建的pytorch环境下安装pytorch版本, 执行命令:
conda install pytorch torchvision cudatoolkit=11.7 -c pytorch
注意:11.7处应为cuda的安装版本号
如果安装不上或者只能安装cpu版本的pytorch, 则可以
手动下载gpu版本的torch和torchversion
- 下载网址:https://download.pytorch.org/whl/torch_stable.html
- 文件名是对应的版本号
这里需要下载与torch对应的torchvision版本。
在Anaconda创建的pytorch环境下,使用 cd 指令移动到下载好的上边两个文件目录下,终端输入以下指令:
pip install torch-1.xx.0-cp38-cp38m-linux_x86_64.whl
pip install torchvision-0.xx.0-xxx.xxx-xxx-xxx.whl我用的指令
pip install torch-1.13.0+cu117.with.pypi.cudnn-cp39-cp39-linux_x86_64.whl
pip install torchvision-0.14.1+cu117-cp39-cp39-linux_x86_64.whl验证cuda可用性
python
import torch
print(torch.cuda.is_available())当输出为 True 时,表明 pytorch 安装成功。
2. Mamba项目克隆和安装
1) causal-conv1d安装
pip install causal-conv1d>=1.2.0一种在Mamba块内部使用的简单因果一维卷积层的高效实现。
2) 克隆Mamba代码
命令行执行下面三条语句
git clone https://github.com/state-spaces/mamba.git
cd mamba
pip install .3)更改模型权重缓存目录
可以配置Hugging Face库使用一个有更多磁盘空间的不同目录来缓存模型。可以设置环境变量 HF_HOME 到一个有足够空间的新位置。这里是如何做的示例,命令行执行下面两条语句:
export HF_HOME=/home/bai/data
export TOKENIZERS_PARALLELISM=trueexport TOKENIZERS_PARALLELISM=true 这条命令主要是在配置环境变量,用于控制并行处理的行为。
在使用某些基于Python的自然语言处理(NLP)库(如 transformers 库)时,这些库会使用多线程来加速任
务。
TOKENIZERS_PARALLELISM 环境变量用来控制在处理数据时是否应启用并行计算的。
设置为 true 表示允许使用并行计算,这样可以在多核CPU上加速数据的处理速度。
反之,如果设置为 false ,则会关闭并行计算,可能因此降低性能。
这个设置通常在你运行涉及大量数据处理的脚本或程序时进行调整,以优化性能和资源使用
4) 执行生成基准测试的脚本
python benchmarks/benchmark_generation_mamba_simple.py --model-name "state-
spaces/mamba-2.8b" --prompt "I had a dream last night and" --topp 0.9 --temperature 0.7
--repetition-penalty 1.2这行命令是用来执行一个 Python 脚本 benchmark_generation_mamba_simple.py ,该脚本位于 benchmarks
文件夹下。
这个脚本的目的是对 state-spaces/mamba-2.8b 这个模型进行文本生成的性能测试。
脚本和参数解释
脚本路径:
- benchmarks/benchmark_generation_mamba_simple.py :指的是运行位于 benchmarks 文件夹下的 benchmark_generation_mamba_simple.py 脚本。
参数:
- --model-name "state-spaces/mamba-2.8b" :指定使用的模型名称为 "state-spaces/mamba-2.8b"。这通常表示模型存储在某个模型库或本地目录中。
- --prompt "I had a dream last night and" :设置生成文本的起始提示。这里的提示是 "I had a dream last night and",模型将基于此开始生成文本。
- --topp 0.9 :使用概率截断抽样(Top-p sampling),0.9 的值意味着从累计概率分布中选择最可能的最小集合,这些集合的累计概率至少为 0.9。这是一种控制生成文本随机性的方法。
- --temperature 0.7 :设置采样温度为 0.7。温度用于调节概率分布的平滑程度,较低的温度(小于1)会使输出更确定性,较高的温度则使输出更随机。
- --repetition-penalty 1.2 :设置重复惩罚为 1.2。这是一种减少生成文本中重复内容的技术,通过惩罚已经生成的词或短语的分数来实现。
Loading model state-spaces/mamba-2.8b
Special tokens have been added in the vocabulary, make sure the associated word
embeddings are fine-tuned or trained.
Number of parameters: 2768345600
['I had a dream last night and I was in the middle of it, but then my mind went blank.
It\'s like when you\'re asleep or dreaming that something happens to your body while
everything else is still there."\n\n"That sounds familiar," said Trey with an amused
smile on his face as he looked at me from across our table where we were sitting
together for breakfast one morning after school before going home early because Mom
needed help around her house again today since she\'d been so busy lately working extra
hours trying desperately not']
Prompt length: 7, generation length: 100
state-spaces/mamba-2.8b prompt processing + decoding time: 1816ms
这里是对输出内容的详细解析:
1. 加载模型:
- Loading model state-spaces/mamba-2.8b :表明正在加载命名为 "state-spaces/mamba-2.8b"的模型,这是一个预训练的语言模型,通常用于处理复杂的文本生成任务。
2. 特殊标记警告:
- Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained. :这表示在模型的词汇表中添加了特殊标记。确保这些特殊标记的词嵌入已经被适当地训练或微调,这对于模型正确理解和处理这些标记至关重要。
3. 模型参数:
- Number of parameters: 2768345600 :模型有大约27.68亿个参数,这说明该模型具有高度的复杂性和学习能力,能够捕捉丰富的语言特征。
4. 生成文本:
- 输出的文本片段是对您提供的提示 "I had a dream last night and" 的回应。生成的内容是一个描述性的场景,涉及主人公在梦中体验到思维空白,随后与朋友Trey在一起早餐时讨论这种感觉。这显示了模型在生成具有情境相关性和连贯性的文本方面的能力。
5. 提示长度和生成长度:
- Prompt length: 7, generation length: 100 :初始提示长度为7个单词,模型生成了100个单词的文本,这显示了模型在接受初始输入并扩展成更长叙述方面的效率。
6. 处理和解码时间:
- state-spaces/mamba-2.8b prompt processing + decoding time: 1816ms :模型处理输入并生成响应的总时间为1816毫秒(约1.816秒)。这提供了模型响应速度的一个基准,有助于评估其在需要快速反应的应用场景中的适用性。



![[图解]SysML和EA建模住宅安全系统-05-参数图](https://img-blog.csdnimg.cn/direct/29df5817b9c24512a6975e17a94d4032.png)